 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeGS-PCR: Effective and Robust 3D Point Cloud Registration with Two-Stage Color-Enhanced Geometric-3DGS Fusion
Apr 20, 2026We address the challenge of point cloud registration using color information, where traditional methods relying solely on geometric features often struggle in low-overlap and incomplete scenarios. To overcome these limitations, we propose GeGS-PCR, a novel two-stage method that combines geometric, color, and Gaussian information for robust registration. Our approach incorporates a dedicated color encoder that enhances color features by extracting multi-level geometric and color data from the original point cloud. We introduce the \textbf{Ge}ometric-3D\textbf{GS} module, which encodes the local neighborhood information of colored superpoints to ensure a globally invariant geometric-color context. Leveraging LORA optimization, we maintain high performance while preserving the expressiveness of 3DGS. Additionally, fast differentiable rendering is utilized to refine the registration process, leading to improved convergence. To further enhance performance, we propose a joint photometric loss that exploits both geometric and color features. This enables strong performance in challenging conditions with extremely low point cloud overlap. We validate our method by colorizing the Kitti dataset as ColorKitti and testing on both Color3DMatch and Color3DLoMatch datasets. Our method achieves state-of-the-art performance with \textit{Registration Recall} at 99.9\%, \textit{Relative Rotation Error} as low as 0.013, and \textit{Relative Translation Error} as low as 0.024, improving precision by at least a factor of 2.
VisionCreator-R1: A Reflection-Enhanced Native Visual-Generation Agentic Model
Mar 09, 2026Visual content generation has advanced from single-image to multi-image workflows, yet existing agents remain largely plan-driven and lack systematic reflection mechanisms to correct mid-trajectory visual errors. To address this limitation, we propose VisionCreator-R1, a native visual generation agent with explicit reflection, together with a Reflection-Plan Co-Optimization (RPCO) training methodology. Through extensive experiments and trajectory-level analysis, we uncover reflection-plan optimization asymmetry in reinforcement learning (RL): planning can be reliably optimized via plan rewards, while reflection learning is hindered by noisy credit assignment. Guided by this insight, our RPCO first trains on the self-constructed VCR-SFT dataset with reflection-strong single-image trajectories and planning-strong multi-image trajectories, then co-optimization on VCR-RL dataset via RL. This yields our unified VisionCreator-R1 agent, which consistently outperforms Gemini2.5Pro on existing benchmarks and our VCR-bench covering single-image and multi-image tasks.
VisionCreator: A Native Visual-Generation Agentic Model with Understanding, Thinking, Planning and Creation
Mar 03, 2026Visual content creation tasks demand a nuanced understanding of design conventions and creative workflows-capabilities challenging for general models, while workflow-based agents lack specialized knowledge for autonomous creative planning. To overcome these challenges, we propose VisionCreator, a native visual-generation agentic model that unifies Understanding, Thinking, Planning, and Creation (UTPC) capabilities within an end-to-end learnable framework. Our work introduces four key contributions: (i) VisGenData-4k and its construction methodology using metacognition-based VisionAgent to generate high-quality creation trajectories with explicit UTPC structures; (ii) The VisionCreator agentic model, optimized through Progressive Specialization Training (PST) and Virtual Reinforcement Learning (VRL) within a high-fidelity simulated environment, enabling stable and efficient acquisition of UTPC capabilities for complex creation tasks; (iii) VisGenBench, a comprehensive benchmark featuring 1.2k test samples across diverse scenarios for standardized evaluation of multi-step visual creation capabilities; (iv) Remarkably, our VisionCreator-8B/32B models demonstrate superior performance over larger closed-source models across multiple evaluation dimensions. Overall, this work provides a foundation for future research in visual-generation agentic systems.
LLMs for High-Frequency Decision-Making: Normalized Action Reward-Guided Consistency Policy Optimization
Mar 03, 2026While Large Language Models (LLMs) form the cornerstone of sequential decision-making agent development, they have inherent limitations in high-frequency decision tasks. Existing research mainly focuses on discrete embodied decision scenarios with low-frequency and significant semantic differences in state space (e.g., household planning). These methods suffer from limited performance in high-frequency decision-making tasks, since high-precision numerical state information in such tasks undergoes frequent updates with minimal fluctuations, and exhibiting policy misalignment between the learned sub-tasks and composite tasks. To address these issues, this paper proposes Normalized Action Reward guided Consistency Policy Optimization (NAR-CP). 1) Our method first acquires predefined dense rewards from environmental feedback of candidate actions via reward functions, then completes reward shaping through normalization, and theoretically verifies action reward normalization does not impair optimal policy. 2) To reduce policy misalignment in composite tasks, we use LLMs to infer sub-observation candidate actions and generate joint policies, with consistency loss ensuring precise alignment between global semantic policies and sub-semantic policies. Experiments on UAV pursuit, a typical high-frequency task, show our method delivers superior performance on independent and composite tasks with excellent generalization to unseen tasks.
SAGE-LLM: Towards Safe and Generalizable LLM Controller with Fuzzy-CBF Verification and Graph-Structured Knowledge Retrieval for UAV Decision
Feb 27, 2026In UAV dynamic decision, complex and variable hazardous factors pose severe challenges to the generalization capability of algorithms. Despite offering semantic understanding and scene generalization, Large Language Models (LLM) lack domain-specific UAV control knowledge and formal safety assurances, restricting their direct applicability. To bridge this gap, this paper proposes a train-free two-layer decision architecture based on LLMs, integrating high-level safety planning with low-level precise control. The framework introduces three key contributions: 1) A fuzzy Control Barrier Function verification mechanism for semantically-augmented actions, providing provable safety certification for LLM outputs. 2) A star-hierarchical graph-based retrieval-augmented generation system, enabling efficient, elastic, and interpretable scene adaptation. 3) Systematic experimental validation in pursuit-evasion scenarios with unknown obstacles and emergent threats, demonstrating that our SAGE-LLM maintains performance while significantly enhancing safety and generalization without online training. The proposed framework demonstrates strong extensibility, suggesting its potential for generalization to broader embodied intelligence systems and safety-critical control domains.
Follow-Your-Canvas: Higher-Resolution Video Outpainting with Extensive Content Generation
Sep 02, 2024This paper explores higher-resolution video outpainting with extensive content generation. We point out common issues faced by existing methods when attempting to largely outpaint videos: the generation of low-quality content and limitations imposed by GPU memory. To address these challenges, we propose a diffusion-based method called \textit{Follow-Your-Canvas}. It builds upon two core designs. First, instead of employing the common practice of "single-shot" outpainting, we distribute the task across spatial windows and seamlessly merge them. It allows us to outpaint videos of any size and resolution without being constrained by GPU memory. Second, the source video and its relative positional relation are injected into the generation process of each window. It makes the generated spatial layout within each window harmonize with the source video. Coupling with these two designs enables us to generate higher-resolution outpainting videos with rich content while keeping spatial and temporal consistency. Follow-Your-Canvas excels in large-scale video outpainting, e.g., from 512X512 to 1152X2048 (9X), while producing high-quality and aesthetically pleasing results. It achieves the best quantitative results across various resolution and scale setups. The code is released on https://github.com/mayuelala/FollowYourCanvas
Follow-Your-Pose v2: Multiple-Condition Guided Character Image Animation for Stable Pose Control
Jun 05, 2024



Pose-controllable character video generation is in high demand with extensive applications for fields such as automatic advertising and content creation on social media platforms. While existing character image animation methods using pose sequences and reference images have shown promising performance, they tend to struggle with incoherent animation in complex scenarios, such as multiple character animation and body occlusion. Additionally, current methods request large-scale high-quality videos with stable backgrounds and temporal consistency as training datasets, otherwise, their performance will greatly deteriorate. These two issues hinder the practical utilization of character image animation tools. In this paper, we propose a practical and robust framework Follow-Your-Pose v2, which can be trained on noisy open-sourced videos readily available on the internet. Multi-condition guiders are designed to address the challenges of background stability, body occlusion in multi-character generation, and consistency of character appearance. Moreover, to fill the gap of fair evaluation of multi-character pose animation, we propose a new benchmark comprising approximately 4,000 frames. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods by a margin of over 35\% across 2 datasets and on 7 metrics. Meanwhile, qualitative assessments reveal a significant improvement in the quality of generated video, particularly in scenarios involving complex backgrounds and body occlusion of multi-character, suggesting the superiority of our approach.
Global and Local Semantic Completion Learning for Vision-Language Pre-training
Jun 12, 2023



Cross-modal alignment plays a crucial role in vision-language pre-training (VLP) models, enabling them to capture meaningful associations across different modalities. For this purpose, inspired by the success of masked language modeling (MLM) tasks in the NLP pre-training area, numerous masked modeling tasks have been proposed for VLP to further promote cross-modal interactions. The core idea of previous masked modeling tasks is to focus on reconstructing the masked tokens based on visible context for learning local-local alignment, i.e., associations between image patches and text tokens. However, most of them pay little attention to the global semantic features generated for the masked data, resulting in a limited cross-modal alignment ability of global representations to local features of the other modality. Therefore, in this paper, we propose a novel Global and Local Semantic Completion Learning (GLSCL) task to facilitate global-local alignment and local-local alignment simultaneously. Specifically, the GLSCL task complements the missing semantics of masked data and recovers global and local features by cross-modal interactions. Our GLSCL consists of masked global semantic completion (MGSC) and masked local token completion (MLTC). MGSC promotes learning more representative global features which have a great impact on the performance of downstream tasks, and MLTC can further enhance accurate comprehension on multimodal data. Moreover, we present a flexible vision encoder, enabling our model to simultaneously perform image-text and video-text multimodal tasks. Experimental results show that our proposed method obtains state-of-the-art performance on various vision-language benchmarks, such as visual question answering, image-text retrieval, and video-text retrieval.
Seeing What You Miss: Vision-Language Pre-training with Semantic Completion Learning
Nov 24, 2022



Cross-modal alignment is essential for vision-language pre-training (VLP) models to learn the correct corresponding information across different modalities. For this purpose, inspired by the success of masked language modeling (MLM) tasks in the NLP pre-training area, numerous masked modeling tasks have been proposed for VLP to further promote cross-modal interactions. The core idea of previous masked modeling tasks is to focus on reconstructing the masked tokens based on visible context for learning local-to-local alignment. However, most of them pay little attention to the global semantic features generated for the masked data, resulting in the limited cross-modal alignment ability of global representations. Therefore, in this paper, we propose a novel Semantic Completion Learning (SCL) task, complementary to existing masked modeling tasks, to facilitate global-to-local alignment. Specifically, the SCL task complements the missing semantics of masked data by capturing the corresponding information from the other modality, promoting learning more representative global features which have a great impact on the performance of downstream tasks. Moreover, we present a flexible vision encoder, which enables our model to perform image-text and video-text multimodal tasks simultaneously. Experimental results show that our proposed method obtains state-of-the-art performance on various vision-language benchmarks, such as visual question answering, image-text retrieval, and video-text retrieval.
Egocentric Video-Language Pretraining @ Ego4D Challenge 2022
Jul 04, 2022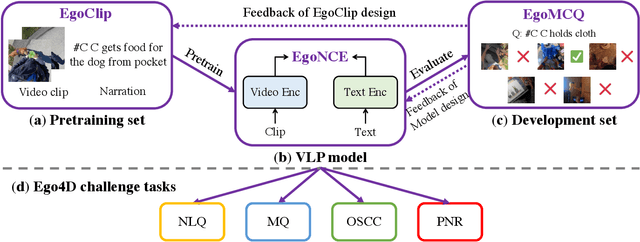
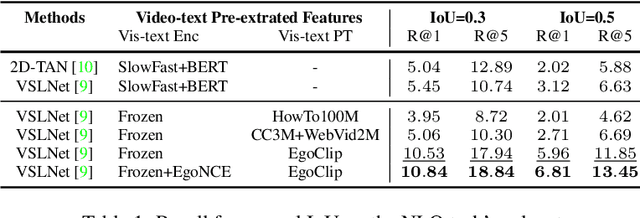
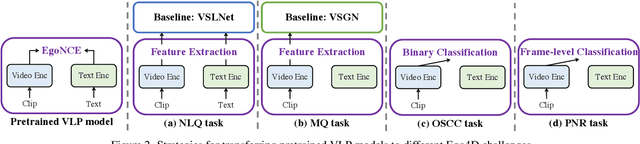
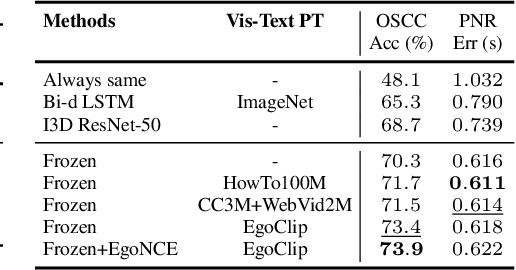
In this report, we propose a video-language pretraining (VLP) based solution \cite{kevin2022egovlp} for four Ego4D challenge tasks, including Natural Language Query (NLQ), Moment Query (MQ), Object State Change Classification (OSCC), and PNR Localization (PNR). Especially, we exploit the recently released Ego4D dataset \cite{grauman2021ego4d} to pioneer Egocentric VLP from pretraining dataset, pretraining objective, and development set. Based on the above three designs, we develop a pretrained video-language model that is able to transfer its egocentric video-text representation or video-only representation to several video downstream tasks. Our Egocentric VLP achieves 10.46R@1&IoU @0.3 on NLQ, 10.33 mAP on MQ, 74% Acc on OSCC, 0.67 sec error on PNR. The code is available at https://github.com/showlab/EgoVLP.